熱線電話:0755-23712116
郵箱:contact@shuangyi-tech.com
地址:深圳市寶安區(qū)沙井街道后亭茅洲山工業(yè)園工業(yè)大廈全至科技創(chuàng)新園科創(chuàng)大廈2層2A


歸并排序是建立在歸并操作上的一種有效的排序算法。該算法是采用分治法(Divide and Conquer)的一個非常典型的應(yīng)用。將已有序的子序列合并,得到完全有序的序列;即先使每個子序列有序,再使子序列段間有序。若將兩個有序表合并成一個有序表,稱為2-路歸并。
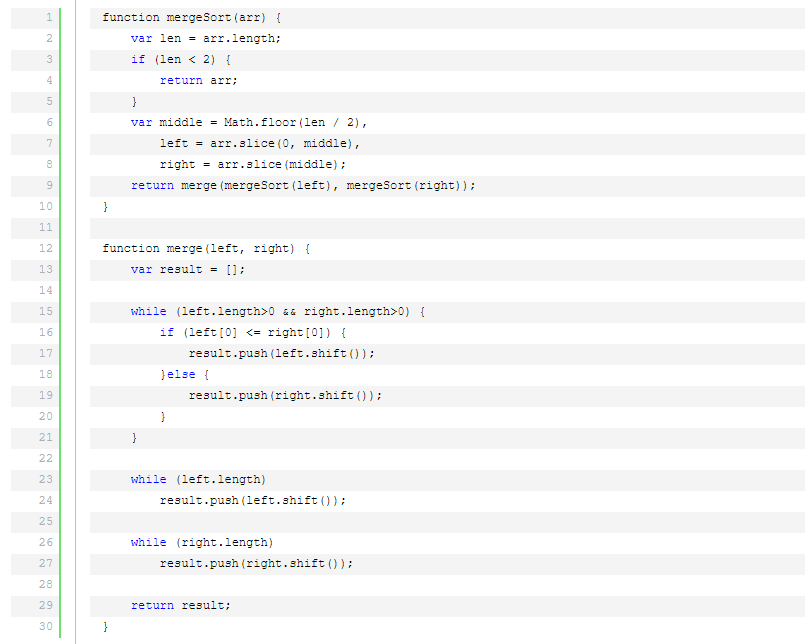
歸并排序是一種穩(wěn)定的排序方法。和選擇排序一樣,歸并排序的性能不受輸入數(shù)據(jù)的影響,但表現(xiàn)比選擇排序好的多,因為始終都是O(nlogn)的時間復(fù)雜度。代價是需要額外的內(nèi)存空間。
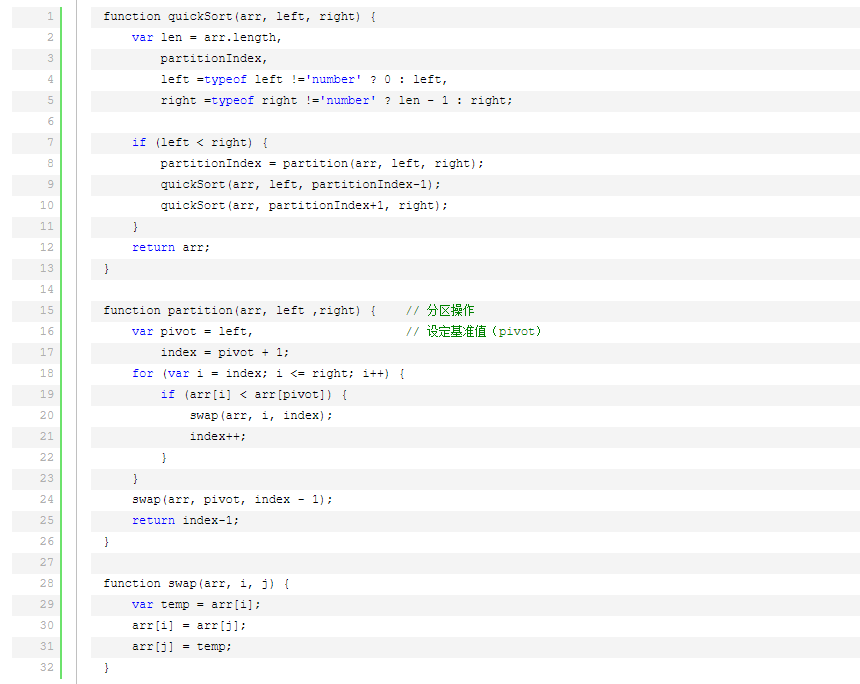
快速排序的基本思想:通過一趟排序?qū)⒋庞涗浄指舫瑟毩⒌膬刹糠郑渲幸徊糠钟涗浀年P(guān)鍵字均比另一部分的關(guān)鍵字小,則可分別對這兩部分記錄繼續(xù)進(jìn)行排序,以達(dá)到整個序列有序。
快速排序使用分治法來把一個串(list)分為兩個子串(sub-lists)。具體算法描述如下:
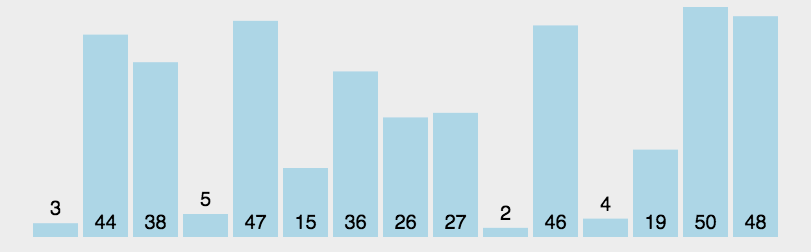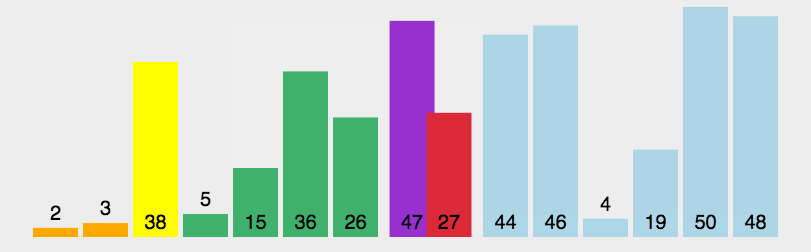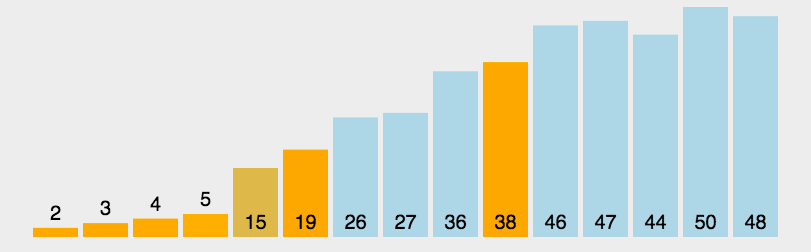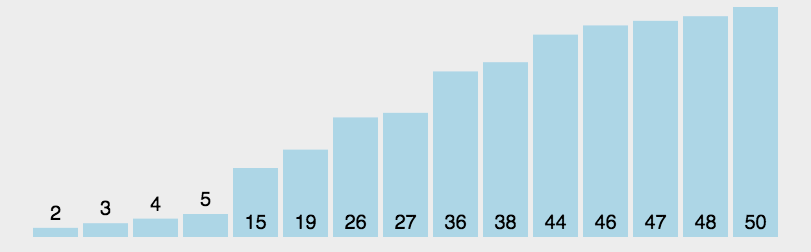
堆排序(Heapsort)是指利用堆這種數(shù)據(jù)結(jié)構(gòu)所設(shè)計的一種排序算法。堆積是一個近似完全二叉樹的結(jié)構(gòu),并同時滿足堆積的性質(zhì):即子結(jié)點的鍵值或索引總是小于(或者大于)它的父節(jié)點。



計數(shù)排序不是基于比較的排序算法,其核心在于將輸入的數(shù)據(jù)值轉(zhuǎn)化為鍵存儲在額外開辟的數(shù)組空間中。 作為一種線性時間復(fù)雜度的排序,計數(shù)排序要求輸入的數(shù)據(jù)必須是有確定范圍的整數(shù)。
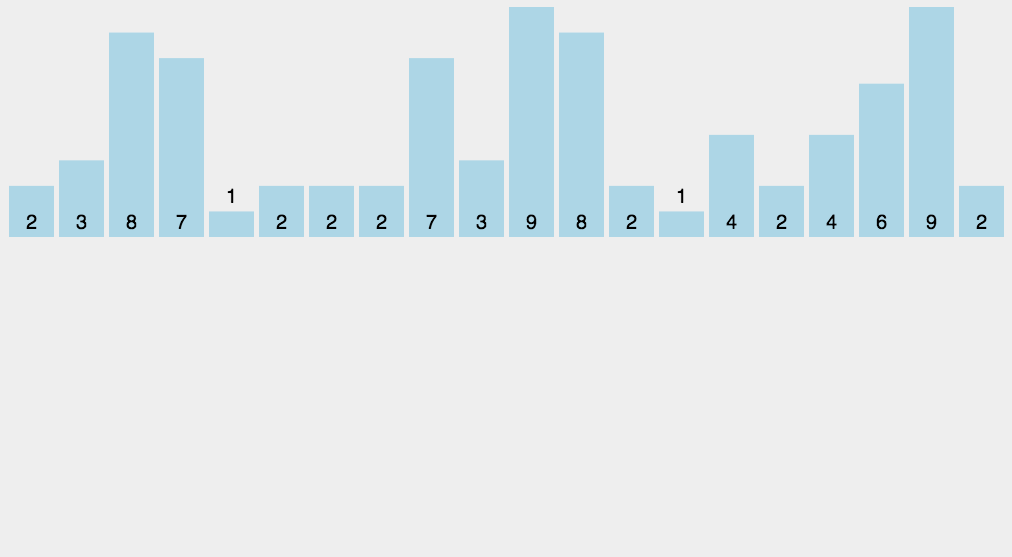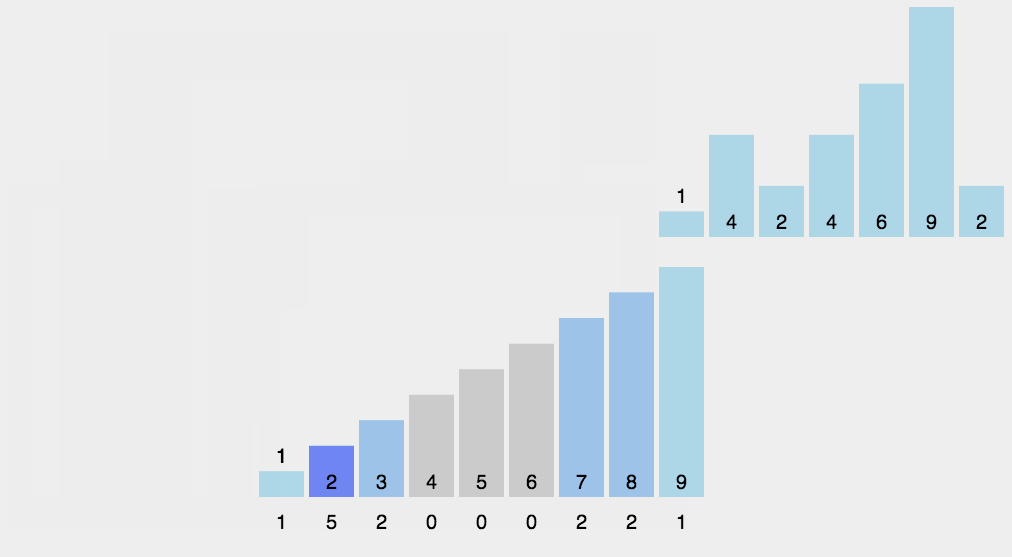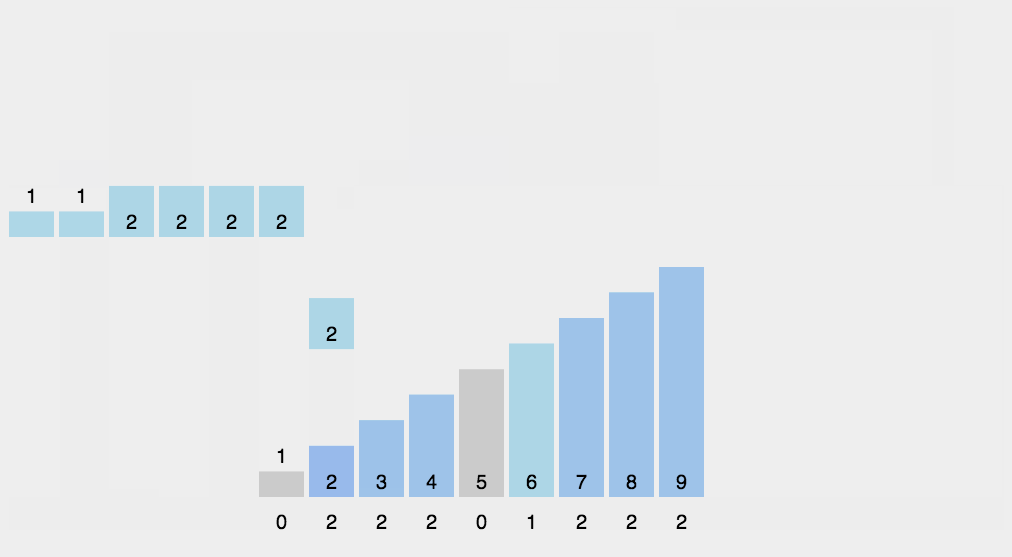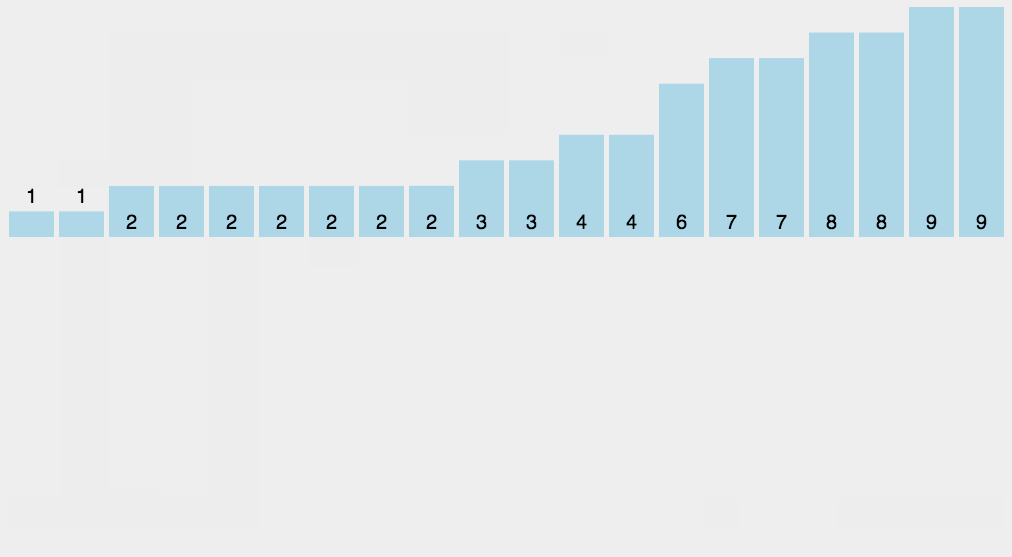
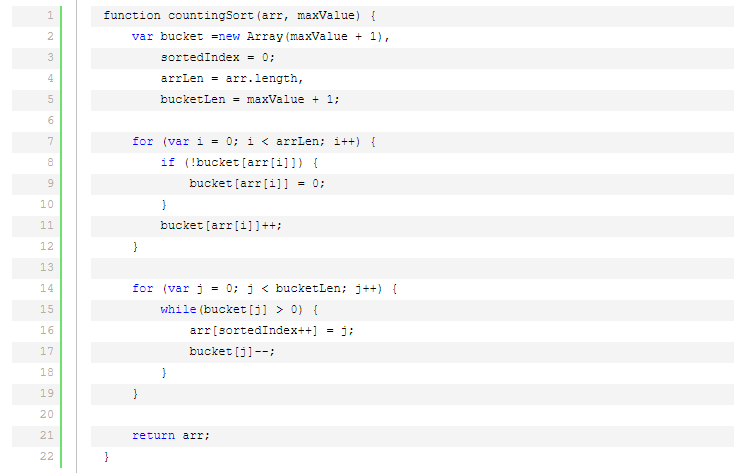
計數(shù)排序是一個穩(wěn)定的排序算法。當(dāng)輸入的元素是 n 個 0到 k 之間的整數(shù)時,時間復(fù)雜度是O(n+k),空間復(fù)雜度也是O(n+k),其排序速度快于任何比較排序算法。當(dāng)k不是很大并且序列比較集中時,計數(shù)排序是一個很有效的排序算法。
桶排序是計數(shù)排序的升級版。它利用了函數(shù)的映射關(guān)系,高效與否的關(guān)鍵就在于這個映射函數(shù)的確定。桶排序 (Bucket sort)的工作的原理:假設(shè)輸入數(shù)據(jù)服從均勻分布,將數(shù)據(jù)分到有限數(shù)量的桶里,每個桶再分別排序(有可能再使用別的排序算法或是以遞歸方式繼續(xù)使用桶排序進(jìn)行排)。

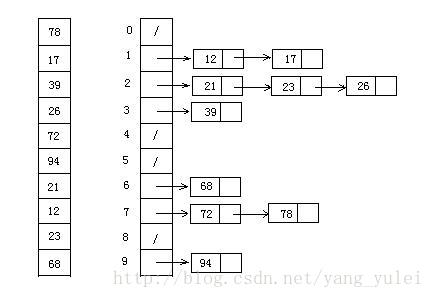

桶排序最好情況下使用線性時間O(n),桶排序的時間復(fù)雜度,取決與對各個桶之間數(shù)據(jù)進(jìn)行排序的時間復(fù)雜度,因為其它部分的時間復(fù)雜度都為O(n)。很顯然,桶劃分的越小,各個桶之間的數(shù)據(jù)越少,排序所用的時間也會越少。但相應(yīng)的空間消耗就會增大。
基數(shù)排序是按照低位先排序,然后收集;再按照高位排序,然后再收集;依次類推,直到最高位。有時候有些屬性是有優(yōu)先級順序的,先按低優(yōu)先級排序,再按高優(yōu)先級排序。最后的次序就是高優(yōu)先級高的在前,高優(yōu)先級相同的低優(yōu)先級高的在前。

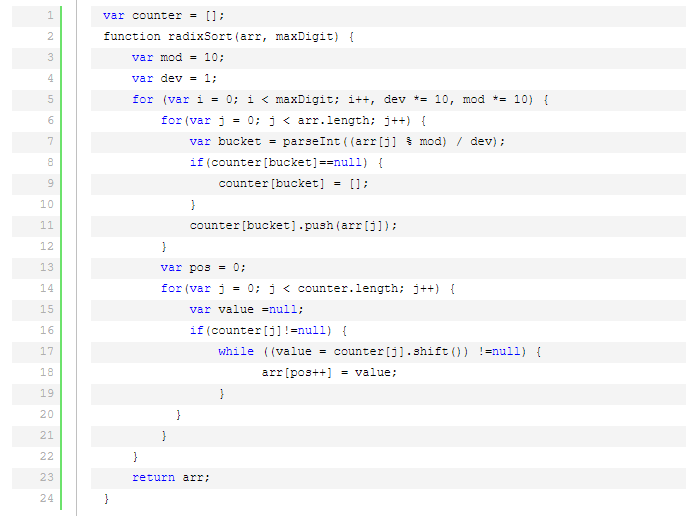
基數(shù)排序基于分別排序,分別收集,所以是穩(wěn)定的。但基數(shù)排序的性能比桶排序要略差,每一次關(guān)鍵字的桶分配都需要O(n)的時間復(fù)雜度,而且分配之后得到新的關(guān)鍵字序列又需要O(n)的時間復(fù)雜度。假如待排數(shù)據(jù)可以分為d個關(guān)鍵字,則基數(shù)排序的時間復(fù)雜度將是O(d*2n) ,當(dāng)然d要遠(yuǎn)遠(yuǎn)小于n,因此基本上還是線性級別的。
基數(shù)排序的空間復(fù)雜度為O(n+k),其中k為桶的數(shù)量。一般來說n>>k,因此額外空間需要大概n個左右。
熱線電話:0755-23712116
郵箱:contact@shuangyi-tech.com
地址:深圳市寶安區(qū)沙井街道后亭茅洲山工業(yè)園工業(yè)大廈全至科技創(chuàng)新園科創(chuàng)大廈2層2A
