熱線電話:0755-23712116
郵箱:contact@shuangyi-tech.com
地址:深圳市寶安區沙井街道后亭茅洲山工業園工業大廈全至科技創新園科創大廈2層2A


正則表達式編程
接下來我們會看到更多的示例。同時,也會看到C++正則表達式API的更多功能。 為了便于下文示例的講解,我們以維基百科上對于正則表達式的介紹文本為基礎。
我們將這段文字保存在名稱為content.txt的文本文件中。下面幾個示例會在這個文本上操作。
在上文中,為了從字符串中查找出所有匹配的字符,我們的做法是遍歷原始字符串的每一個子字符串來進行查找,這樣做很明顯效率很低。更好的做法當然是使用迭代器。
在一大段文本中查找所有匹配的目標,這是一個非常常見的需求。而迭代器正好滿足這一需求,它會依次返回它從文本中找到的匹配內容。
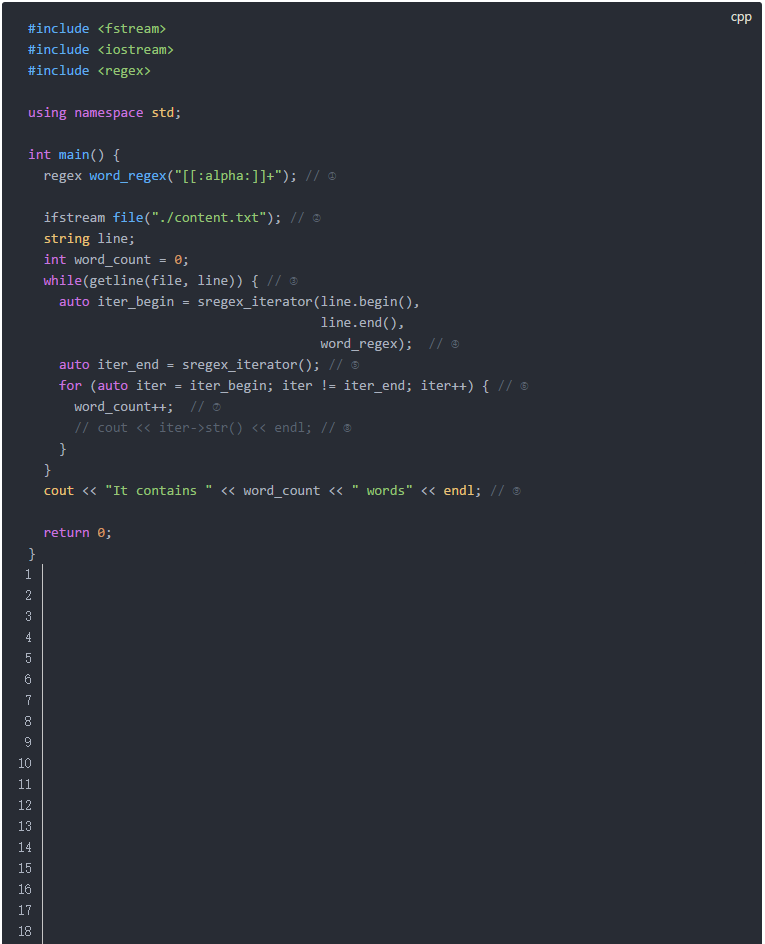
這段代碼的說明如下:
ifstream讀取文本文件 這段代碼輸出如下:

接下來的幾個代碼示例的主體結構和這里會很相似,我們總是先打開文本文件,然后讀取每一行來進行處理。
前面的示例中我們已經看到,通過std::regex并傳遞字符串就可以構造正則表達式對象。實際上,除了std::regex,還有寬字符版本的std::wregex。它們都源自std::basic_regex

在創建正則表達式對象的時候,除了描述規則本身的字符串之外,還可以傳遞一個flag_type類型的參數,該參數的值定義在std::regex_constants::syntax_option_type中。它們中與“文法”相關的已經在上文介紹過了。

這其中,第一個是我們最常用的。
思路:單詞的首字母有些會大寫,我們可以通過[Rr]來匹配大寫或者小寫的R字母,但實際上,使用icase無疑會更方便。
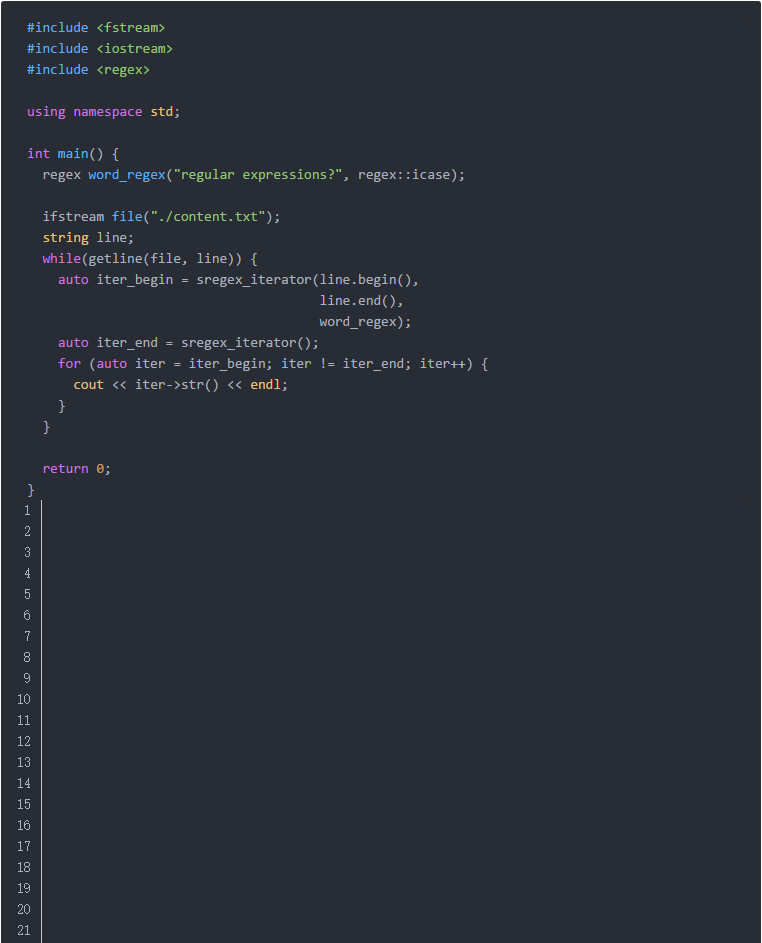
這段代碼與前面的結構是一樣的,我們最需要關注的可能就是下面這一行:

通過std::regex::icase我們指定了這個正則表達式是不區分大小寫的。
另外還有一個值得注意的就是正則表達式末尾的...s?,它意味著單詞可能是單數或者復數,因此結尾的“s”可以出現0次或者1次。
這段代碼輸出如下:

std::match_results用來存儲匹配結果。與迭代器類似,匹配結果也有四種類型:
當我們使用正則表達式時,我們的目標常常不單單是判斷或者查找完整匹配的內容。而是需要捕獲匹配結果中的子串。例如:我們不僅要匹配出日期,還要捕獲日期中的年份,月份等信息。這個時候就要使用分組功能。
我們在介紹正則表達式特殊字符的時候,提到過圓括號(和)。它們的作用就是分組。當你在正則表達式中配對的使用圓括號時,就會形成一個分組,一個正則表達式中可以包含多個分組。分組通過編號0, 1, 2, …來區分。編號0的分組是匹配的整體,其他編號根據括號的順序來確定。
這些分組最終可以在匹配完成之后,可以通過std::match_results的API來獲取。這些API如下表所示:
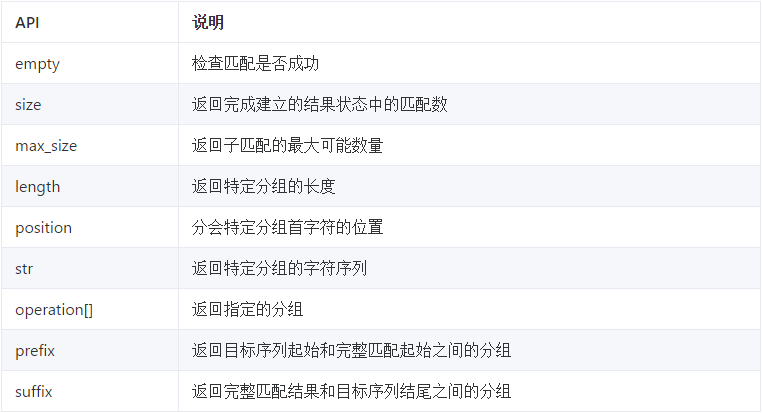
在C++中,分組叫做子匹配(sub_match)。std::sub_match 這個類型只有一個默認構造函數,通常你不會主動創建它,而是使用std::match_results的接口來獲取它的對象。
示例:查找出文本中所有的年代,并分離出世紀的部分和年份的部分。 思路:年代的格式是四位數字加上“s”作為后綴。我們可以通過分組的形式分離出兩個部分。圖示如下:

代碼示例:
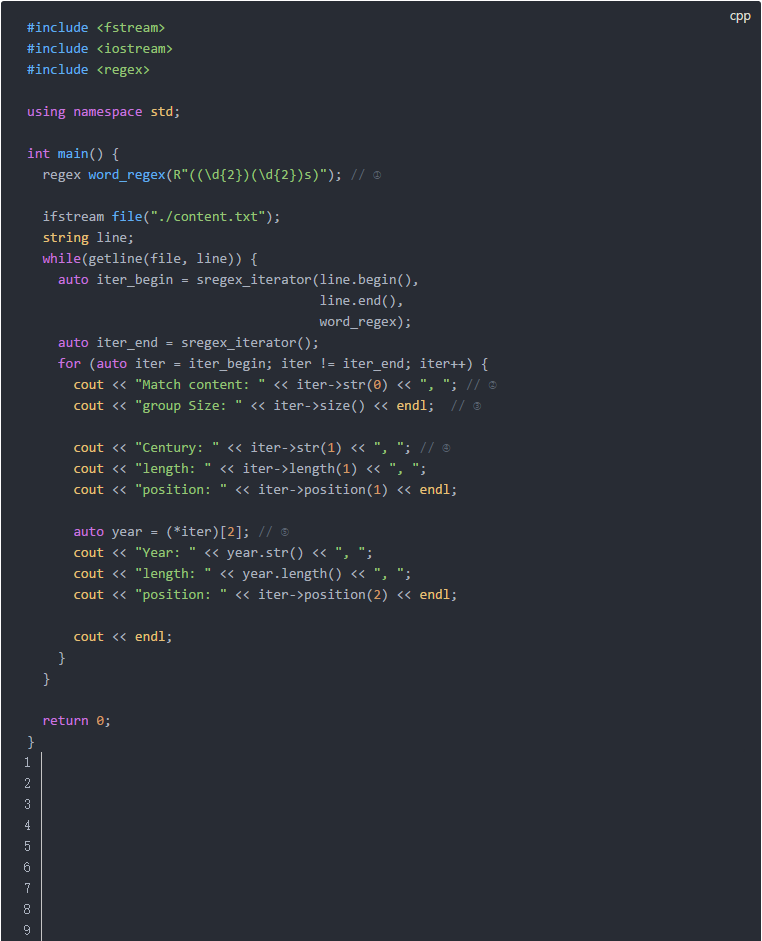
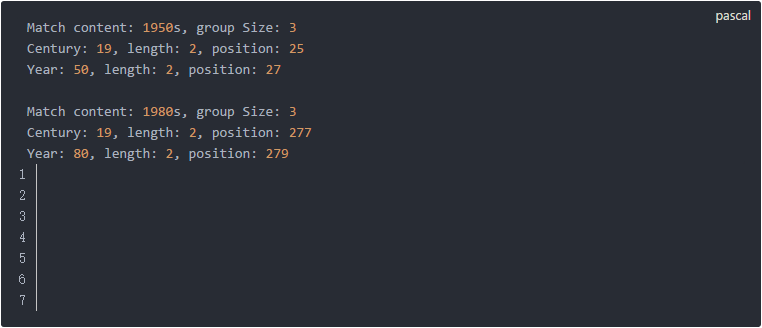
這段代碼說明如下:
sub_match 這段代碼輸出如下:
還是以content.txt的內容為基礎,現在假設我們的目標是:找出所有雙引號中的內容。
根據之前的知識,你可能很輕松就寫出了下面這個正則表達式:

.+ 但是當你運行程序的時候卻發現它可能有點問題。它捕獲的結果是:

為什么?其實很簡單,因為雙引號本身也可以與.匹配。上面這個正則表達式的含義是:匹配一個兩端是雙引號,中間是任意文字的內容。

而將整個文本交給正則表達式的時候,它找出了最長的那個串。可見,原先的正則表達式太過“貪婪”(greedy)。是的,量詞在默認情況都是貪婪的。即:它們會盡可能多的占有內容。

小結一下:

錨點是一類特殊的標記,它們不會匹配任何文本內容,而是尋找特定的標記。你可以簡單理解為它是原先表達式的基礎上增加了新的匹配條件。如果條件不滿足,則無法完成匹配。
錨點主要分為三種:

下面是代碼示例:
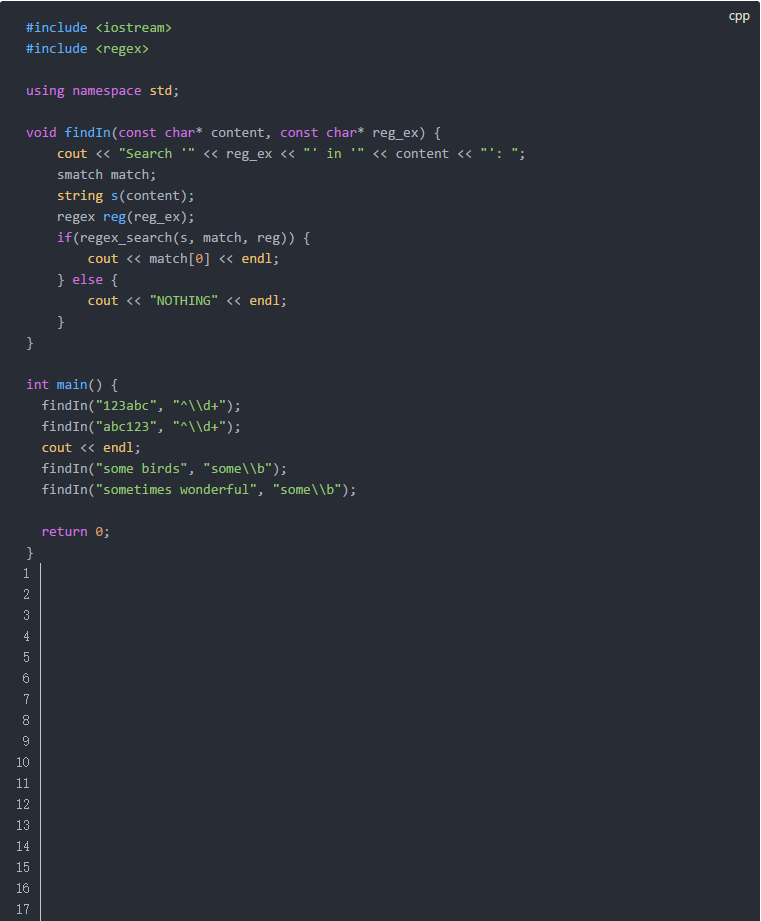
它的輸出如下:
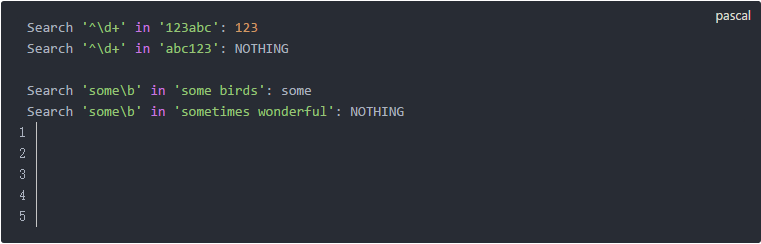
現在假設我們有下面兩個需求:
對于第一個問題,我們可以分兩步:先找出所有的單詞sometimes,然后取前四個字符。對于第二個問題,我們可以先找出所有的單詞“some”,然后把后面是“birds”的丟掉。
以上的解法都是分兩步完成。但實際上,借助環視(lookaround)我們可以一步就完成任務。
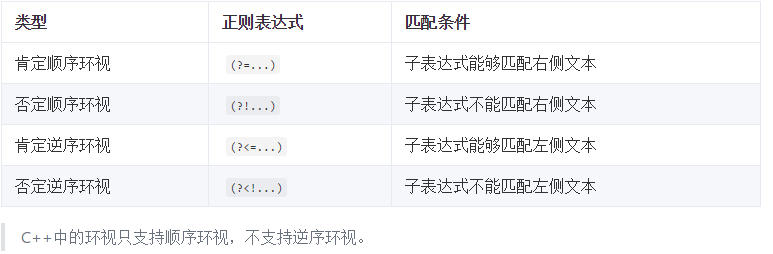
環視是對匹配位置的附加條件,只有條件滿足時才能完成匹配。環視有:順序(向右),逆序(向左),肯定和否定一共四種:
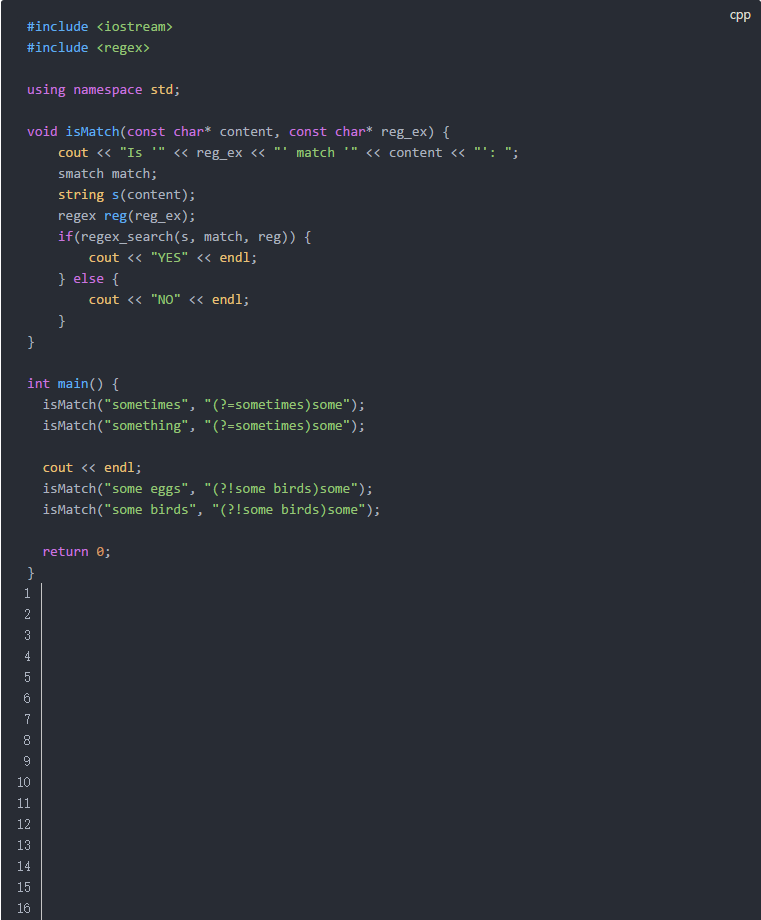
環視說起來有些拗口,但看具體的例子就容易理解了:
這段代碼并不復雜所以就不多做說明,它的輸出結果如下:
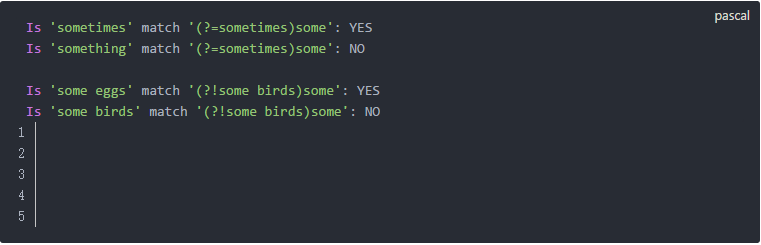
對于包含環視的正則表達式來說,環視之外的內容是匹配的主體,環視本身只是一個附件條件。(?=sometimes)這個肯定順序環視要求從這個位置開始,接下來的字符串必須是"sometimes"才能完成匹配。(?!some birds)這個否定順序環視要是接下來的字符串一定不能是"some birds"才能完成匹配。

接下來,搜索位置往后走一個字符:

這個過程可以一直進行,直到匹配完"some":

雖然正則表達式的主體"some"完成了匹配,但是接下來環視的條件卻無法滿足,于是匹配失敗:

但是,如果要匹配內容正好是"sometimes",則條件是滿足的,于是就完成了匹配。

熱線電話:0755-23712116
郵箱:contact@shuangyi-tech.com
地址:深圳市寶安區沙井街道后亭茅洲山工業園工業大廈全至科技創新園科創大廈2層2A
